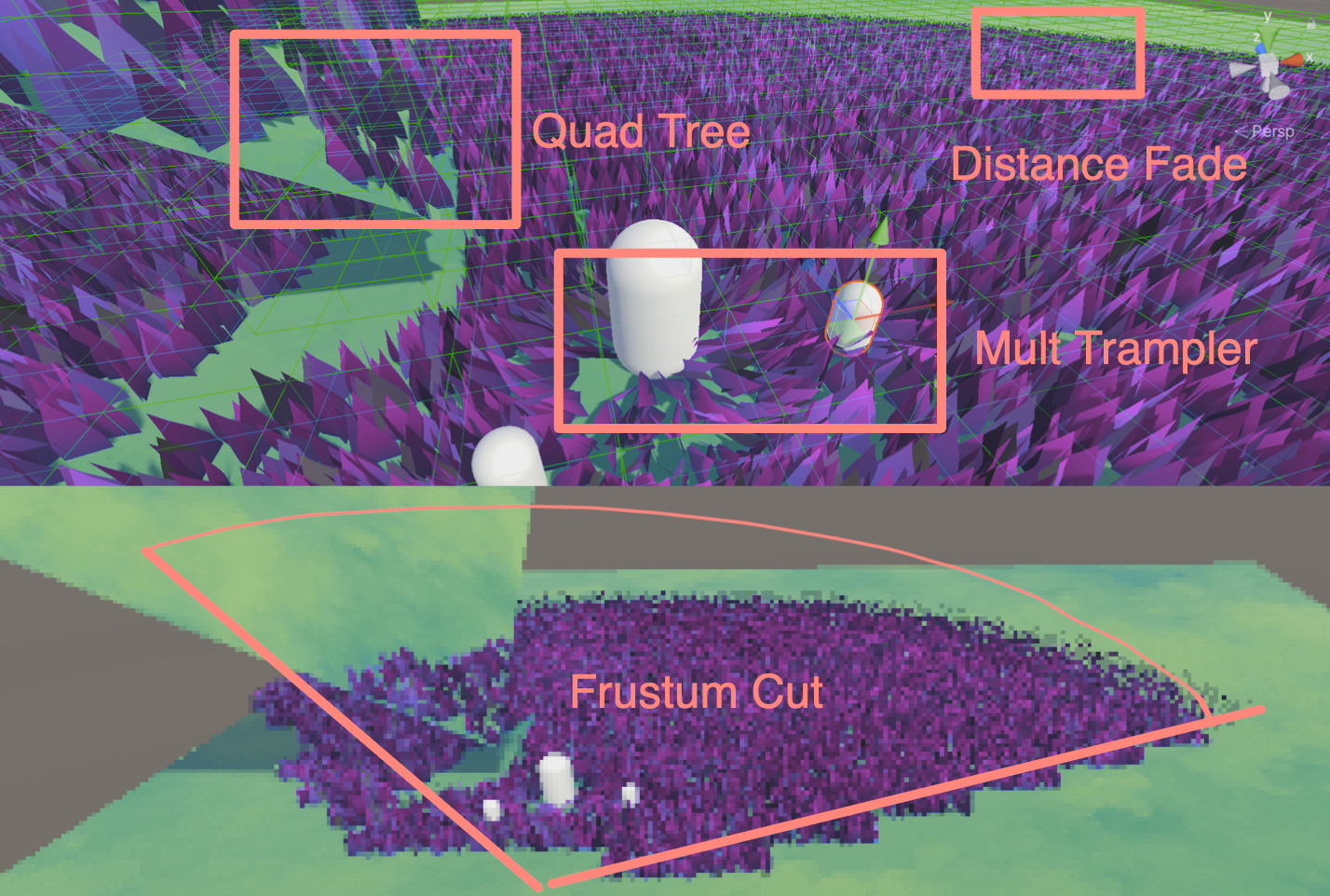
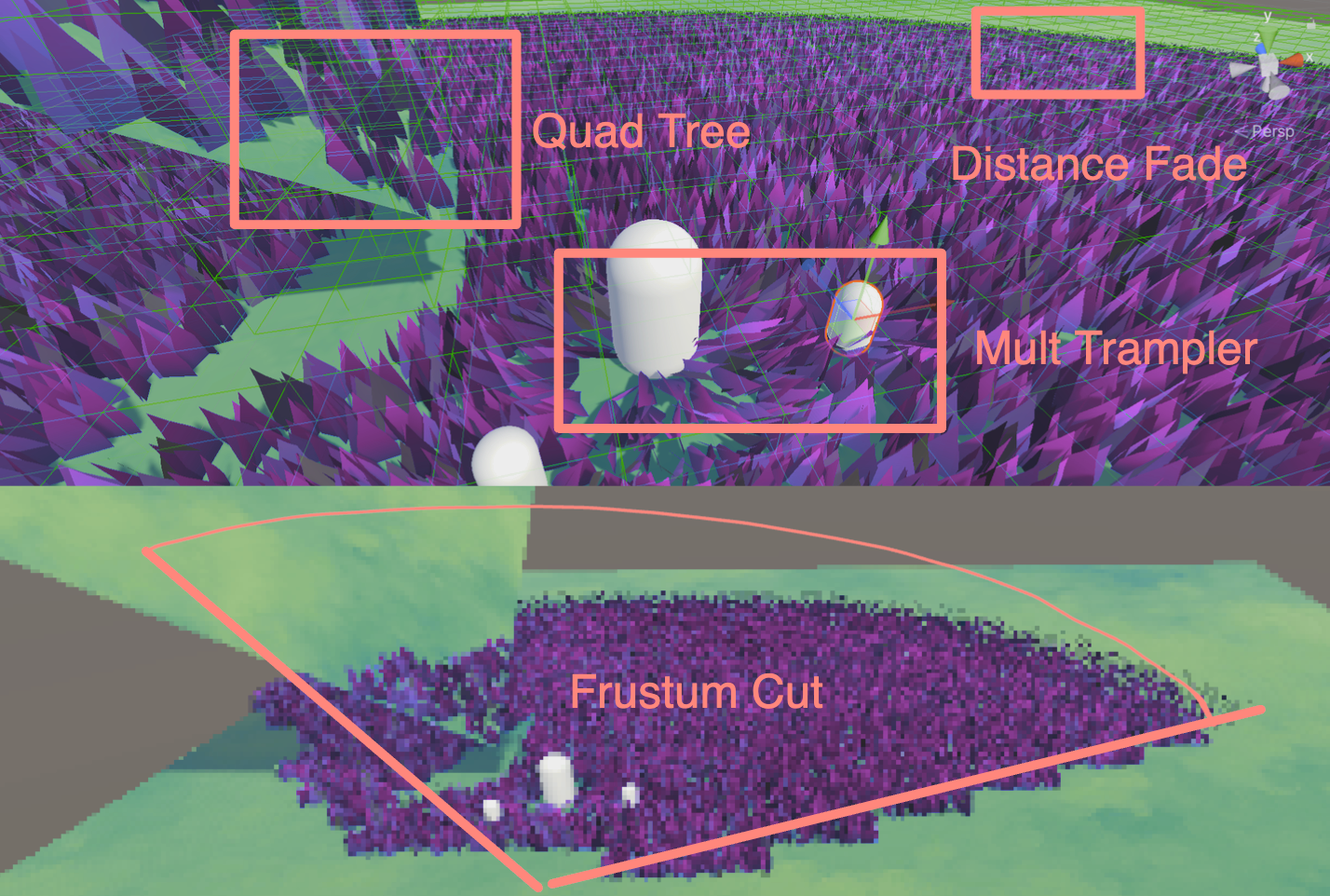
标签 :入门/Shader/曲面细分着色器/Displacement贴图/LOD/平滑轮廓/Early Culling
tessellation(镶嵌)一词是指一大类设计活动,通常是指在平坦的表面上,用各种几何形状的瓷砖相邻排列以形成图案。它的目的可以是艺术性的或实用性的,很多例子可以追溯到几千年前。 — Tessellation, Wikipedia, accessed July 2020.
本文主要參考:
游戏开发中的曲面细分一般是在一个三角形平面(或者是Quad)中做细分(增加顶点数量),然后用Displacement贴图来做顶点位移,或者是用本文实现的Phong细分或者PN triangles细分来做顶点位移。
Phong细分不需要知道相邻的拓扑信息,仅仅用插值计算,比PN triangles等算法效率更高。GAMES101上提到的Loop and Schaefer利用低度数四边形曲面近似Catmull-Clark曲面,这些方法输入的多边形都被一个多项式曲面替代。而本文的Phong细分不需要任何修正额外的几何区域的操作。
一、曲面细分流程概述
这章内容是曲面细分在渲染管线流程的介绍。
曲面细分着色器位于顶点着色器之后,且曲面细分分为三个步骤:Hull、Tesselllator和Domain,其中Tessellator不可编程。

曲面细分的第一个步骤是曲面细分控制着色器(也称为Tessellation Control Shader,TCS),这个着色器将会输出控制点和细分因子。这个阶段主要由两个并行的函数组成:Hull Function和Patch Constant Function。

这两个函数都接收一个个的Patch,即一组顶点索引,比如三角形则用三个数字表示顶点的索引。其中一个Patch就可以组成一个片元,比方说一个三角形片元就是由三个顶点索引组成的。
并且,Hull Function每个顶点执行一次,Path Constant Function每个Patch执行一次,前者输出修改后的控制点数据(通常包括顶点位置、可能的法线、纹理坐标等属性),后者则输出整个片元相关的常量数据,即细分因子。细分因子会告诉下一个阶段(镶嵌器Tessellator)如何对每个片元进行细分。
笼统地讲,Hull Function修改每个控制点,而Patch Constant Function确定基于摄像机距离的细分级别。

接下来进入不可编程阶段,镶嵌器(tessellator)。他接收Patch和刚刚得到的细分因子。镶嵌器会为每一个顶点数据生成一个重心坐标(Barycentric coordinates)。

紧接着来到最后一步,域阶段(Domain Stage,也称为Tessellation Evaluation Shader,TES),这是可编程的。这个部分由域函数组成,每个顶点执行一次。接收重心坐标、Patch和Hull Stage中两个函数生成的结果。大多数逻辑都在这个地方编写。最重要的是你可以在这个阶段重新定位顶点,这是曲面细分中最重要的环节。

如果有几何着色器,他将会在Domain Stage后执行。但是如果不用,则来到光栅化阶段。

总结,最开始是顶点着色器。Hull阶段接受顶点数据,决定如何细分Mesh。然后通过tessellator阶段处理细分网格,最后由Domain阶段为片元着色器输出顶点。
二、曲面细分分析
这章内容是Unity曲面细分的代码分析,实际例子效果展示和底层原理概述。
2.1 关键代码分析
2.1.1 Unity曲面细分基本设置
首先曲面细分着色器需要使用shader target 5.0。
HLSLPROGRAM
#pragma target 5.0 // 5.0 required for tessellation
#pragma vertex Vertex
#pragma hull Hull
#pragma domain Domain
#pragma fragment Fragment
ENDHLSL2.1.2 Hull Stage代码1 – Hull Function
经典的流程,顶点着色器将位置和法线信息转为世界空间。然后将输出结果传递到Hull Stage中。需要注意的是,和顶点着色器不同,Hull着色器的顶点使用 INTERNALTESSPOS 语义而不是 POSITION 语义来表示。原因在于Hull不需要将这些顶点位置输出到下一个渲染流程,而是用于自身内部曲面细分的算法,所以会将这些顶点转换到更适合曲面细分的坐标系统。除此之外开发者也能更加清晰区分。
struct Attributes {
float3 positionOS : POSITION;
float3 normalOS : NORMAL;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct TessellationControlPoint {
float3 positionWS : INTERNALTESSPOS;
float3 normalWS : NORMAL;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
TessellationControlPoint Vertex(Attributes input) {
TessellationControlPoint output;
UNITY_SETUP_INSTANCE_ID(input);
UNITY_TRANSFER_INSTANCE_ID(input, output);
VertexPositionInputs posnInputs = GetVertexPositionInputs(input.positionOS);
VertexNormalInputs normalInputs = GetVertexNormalInputs(input.normalOS);
output.positionWS = posnInputs.positionWS;
output.normalWS = normalInputs.normalWS;
return output;
}下面是Hull Shader的一些设置参数。
第一行domain是定义曲面细分着色器的域类型,意味着输入输出都是三角形图元。可以选tri(三角形)、quad(四边形)等。
第二行outputcontrolpoints 则表示输出控制点的数量,3对应三角形的三个顶点。
第三行outputtopology表示细分后图元的拓扑结构,triangle_cw意思是输出三角形的顶点按照顺时针排序,正确的顺序可以确保表面正面朝外。triangle_cw(顺时针环绕三角形)、triangle_ccw(逆时针环绕三角形)、line(线段)
第四行patchconstantfunc就是Hull Stage的另外一个函数,输出的是细分因子等常量数据。一个Patch只执行一次。
第五行partitioning,分割模式,指定了如何分配额外的顶点到原始Path图元的边上,这一步可以让细分过程更加的平滑均匀。integer,fractional_even,fractional_odd。
第六行的maxtessfactor表示最大细分因子,限制最大的细分可以控制渲染负担。
[domain("tri")]
[outputcontrolpoints(3)]
[outputtopology("triangle_cw")]
[patchconstantfunc("patchconstant")]
[partitioning("fractional_even")]
[maxtessfactor(64.0)]在Hull Shader中,每一个控制点都会被独立调用一次,所以这个函数要执行控制点数量的次数。要知道当前正在处理的是哪一个顶点,我们用语义为 SV_OutputControlPointID 的变量 id 来判断。函数还传入一个特殊的结构,该结构可以像使用数组一样方便的取用Patch里面的任意一个控制点。
TessellationControlPoint Hull(
InputPatch<TessellationControlPoint, 3> patch, uint id : SV_OutputControlPointID) {
TessellationControlPoint h;
// Hull shader code here
return patch[id];
}2.1.3 Hull Stage代码2 – Patch Constant Function
除了Hull Shader,Hull Stage里还有一个函数与之并行,patch constant function。这个函数的签名比较简单,输入一个patch,输出计算后的细分因子。输出结构包含了为三角形每条边指定的鑲嵌因子。这些因子通过特殊的系统值语义 SV_TessFactor 进行标识。每个鑲嵌因子定义了相对应边应该被细分成多少小段,从而影响最终生成的网格的密度和细节。下面具体来看看这个因子具体包含了什么。
struct TessellationFactors {
float edge[3] : SV_TessFactor;
float inside : SV_InsideTessFactor;
};
// The patch constant function runs once per triangle, or "patch"
// It runs in parallel to the hull function
TessellationFactors PatchConstantFunction(
InputPatch<TessellationControlPoint, 3> patch) {
UNITY_SETUP_INSTANCE_ID(patch[0]); // Set up instancing
// Calculate tessellation factors
TessellationFactors f;
f.edge[0] = _FactorEdge1.x;
f.edge[1] = _FactorEdge1.y;
f.edge[2] = _FactorEdge1.z;
f.inside = _FactorInside;
return f;
}首先TessellationFactors结构体里面有一个边缘镶嵌因子 edge[3] ,标记为 SV_TessFactor 。当使用三角形作为基本图元细分时,每条边被定义为位于与具有相同索引的顶点相对的位置。具体说是:边0对应顶点1和顶点2之间。边1对应顶点2和顶点0之间。边2对应顶点0和顶点1之间。为什么这样?直观解释是,边的索引与它不连接的那个顶点的索引相同。这有助于在编写Shader代码时快速识别和处理与特定顶点相对应的边。
还有一个中心镶嵌因子 inside 标记为 SV_InsideTessFactor 。这个因子直观改变最终镶嵌的图案,更本质的说是决定了边缘细分的次数,用于控制三角形内部的细分密度。与边的细分因子相比,中心镶嵌因子控制的是三角形内部如何被进一步细分成更小的三角形,而边缘镶嵌因子影响边缘细分的次数。
Patch Constant Function还可以输出其他有用的数据,但是必须标注正确的语义。比方说BEZIERPOS语义就非常有用,可以表示float3的数据。稍后将会使用这个语义输出基于贝塞尔曲线的平滑算法控制点。
2.1.4 Domain Stage代码
接下来就进入Domain Stage。Domain Function也有一个Domain属性,应该与Hull Function的输出拓扑类型相同,该例子设置为三角形。这个函数输入来自Hull Function的Patch、Patch Constant Function的输出以及最重要的顶点重心坐标。输出结构非常接近顶点着色器的输出结构,包含Clip空间的位置,以及片元着色器所需要的照明数据。
暂时不知道干嘛的没关系,读到本文第四章再跳回来研究。
简单的说就是,细分出来的每一个新顶点都会跑一边这个domain函数。
struct Interpolators {
float3 normalWS : TEXCOORD0;
float3 positionWS : TEXCOORD1;
float4 positionCS : SV_POSITION;
};
// Call this macro to interpolate between a triangle patch, passing the field name
#define BARYCENTRIC_INTERPOLATE(fieldName) \
patch[0].fieldName * barycentricCoordinates.x + \
patch[1].fieldName * barycentricCoordinates.y + \
patch[2].fieldName * barycentricCoordinates.z
// The domain function runs once per vertex in the final, tessellated mesh
// Use it to reposition vertices and prepare for the fragment stage
[domain("tri")] // Signal we're inputting triangles
Interpolators Domain(
TessellationFactors factors, // The output of the patch constant function
OutputPatch<TessellationControlPoint, 3> patch, // The Input triangle
float3 barycentricCoordinates : SV_DomainLocation) { // The barycentric coordinates of the vertex on the triangle
Interpolators output;
// Setup instancing and stereo support (for VR)
UNITY_SETUP_INSTANCE_ID(patch[0]);
UNITY_TRANSFER_INSTANCE_ID(patch[0], output);
UNITY_INITIALIZE_VERTEX_OUTPUT_STEREO(output);
float3 positionWS = BARYCENTRIC_INTERPOLATE(positionWS);
float3 normalWS = BARYCENTRIC_INTERPOLATE(normalWS);
output.positionCS = TransformWorldToHClip(positionWS);
output.normalWS = normalWS;
output.positionWS = positionWS;
return output;
}这个函数,Unity会给我们细分因子、Patch的三个顶点还有当前的新顶点的重心坐标。我们可使用这些数据做位移处理等。
2.2 细分因子与划分模式详解
从这个链接 拷贝代码,然后制作对应的材质,并且开启线框模式。我们目前只为Mesh绘制了顶点,并没有在片元着色器应用任何操作,因此看上去是透明的。

如果将Edge因子任意一个分量设置为0或者小于0,那么Mesh就会完全消失。下图就是消失后的样子(打开了Unity编辑器的物体边框描边),这个特性十分重要。

2.2.1 细分因子概述
说白了,这些个因子在Hull Stage设置了之后,就只是简单粗暴的在Tessellation Stage中写进重心坐标里,比如说边缘因子、内部因子。(假设都是tri,如果是quad则是用uv来计算,可能会更加复杂,我不知道)这个简单粗暴的阶段并不可编程。

以“整数(均匀)切割模式”为例子。(暂时) [partitioning(“integer”)] domain都是三角形 [domain(“tri”)] 输出的顶点数量也是3。 [outputcontrolpoints(3)] 并且输出的拓扑结构是三角形顺时针。 [outputtopology(“triangle_cw”)]
2.2.2 准备工作与潜在的并行问题
将代码修改改为如下:
// .shader
_FactorEdge1("[Float3]Edge factors,[Float]Inside factor", Vector) = (1, 1, 1, 1) // -- Edited --
// .hlsl
float4 _FactorEdge1; // -- Edited --
...
f.edge[0] = _FactorEdge1.x;
f.edge[1] = _FactorEdge1.y; // -- Edited --
f.edge[2] = _FactorEdge1.z; // -- Edited --
f.inside = _FactorEdge1.w; // -- Edited --
这里可能会存在一个问题。有时候编译器会拆分Patch Constant Function并行计算每一个因子,这就导致有时候一些因子被删除了,可能会到看因子会莫名其妙等于0。解决方法是将这些因子打包成一个向量,这样编译器就不会使用未定义的量。下面简单复现一下可能会发生的情况。
修改Path Constant Function如下,并且在面板中开放两个新的属性。
修改的代码行后注释了 // — Edited — 。
// The patch constant function runs once per triangle, or "patch"
// It runs in parallel to the hull function
TessellationFactors PatchConstantFunction(
InputPatch<TessellationControlPoint, 3> patch) {
UNITY_SETUP_INSTANCE_ID(patch[0]); // Set up instancing
// Calculate tessellation factors
TessellationFactors f;
f.edge[0] = _FactorEdge1.x;
f.edge[1] = _FactorEdge2; // -- Edited --
f.edge[2] = _FactorEdge3; // -- Edited --
f.inside = _FactorInside;
return f;
}
_FactorEdge2("Edge 2 factor", Float) = 1 // -- Edited --
_FactorEdge3("Edge 3 factor", Float) = 1 // -- Edited --2.2.3 边缘因子效果 Edge Factor – SV_TessFactor
可以看到边缘因子Edge Factors大约对应于对应边缘被分割的次数,内部因子Inside Factor对应中心的复杂度。
边缘因子只会影响在原本三角形边上的细分。至于内部复杂的图案,就交给内部因子Inside Factor和划分模式来控制。
需要注意的是,“整数切割模式”的曲面细分都是向上取整。比如2.1取3。

一张图说明一切。

2.2.4 内部因子 Inside Factor – SV_InsideTessFactor
还是INTEGER模式举例子。内部因子只会影响内部图案的复杂程度,具体怎么影响,下面详细介绍。概括一下就是,边缘因子会影响最外层与第一层之间的三角形细分,内部因子会影响到底有多少层,而划分模式则是会影响内部每层是怎么细分的。
假设Edge Factors设置为 (2,3,4) ,只修改Insider Factor,可以观察到一个有趣的性质:当内部因子 n 是偶数时,可以找到一个顶点的坐标恰好位于重心的位置 (13,13,13) 。
一般边缘因子Edge Factors设置为一样的数就好了。这里设置成不同的数,图可能会比较混乱,但是可以看到最本质的规律。

进一步还能观察到,任意一条最靠近最外层三角形的边的顶点数量和内部因子Inside Factor ( n )有一个等量关系: n=Numpoint−1 。即,这条边上的顶点数永远等于细分因子减 1 。

每一层的顶点数量都会减少1。也就是说,第一层(最外围的不算,因为不会细分)会有 n 个顶点,向内第二层会有 n−2 个顶点,以此类推。
综合上面三个观察,我们可以得到一个猜测和结论(没啥用,但是闲着没事算了一下)。内部总顶点数量可以用公式计算,这里的n对应内部因子的n-1,需要注意一下,因为内部因子是从2开始取的: a2n=3n2a2n−1=3n(n−1)+1 最终可以化简合并为: ak=−0.125(−1)k+0.75k2+0.125 全部为整数int运算的公式如下: ak=⌊−(−1)k+6k2+18⌋

2.2.5 划分模式 – [partitioning(“_”)]
上面只说了最简单的均匀划分integer,这种情况会使用整数倍数进行细分。接下来说说其他几种。简单的说,Fractional Odd 和 Fractional Even是Integer的进阶版,但是前者是Integer取奇数情况下的进阶版,后者是Integer取偶数情况下的进阶版。具体进阶在可以用小数部分使得划分不再是平均的。

Fractional Odd (分数奇数):Inside Factor可以是分数(不会被Ceil),且分母为奇数。注意这里说的分母其实是每一个顶点的重心坐标所表示的分母。奇数作为分母的的划分方式一定会让一个顶点落在三角形的重心上,偶数的就不是。这里搬运一下凯奥斯的图。

Fractional Even (分数偶数):与fractional_odd类似,但分母为偶数。具体怎么选我也不清楚。

Pow2 (2的幂次方):此模式仅允许使用2的幂次方(如1, 2, 4, 8等)作为细分级别。一般用在纹理映射或阴影计算。
三、细分优化
3.1 视锥体剔除
生成如此多的顶点会导致性能相当糟糕!因此需要采用一些方法提高渲染效率。虽然在T光栅化之前,会将在视锥体之外的顶点进行剔除,但是如果在TCS中提前把没必要进行细分的Patch剔除了,这样就会减少曲面细分着色器的计算压力。
在Patch Constant Function种将曲面细分因子设置为0,那么曲面细分器就会忽略这个Patch。也就是说这里的剔除是对一整个Patch剔除,而不是视锥体剔除中精细到顶点的剔除。
我们测试Patch中的每一个点,看看他们是否都在视野之外。为此,将Patch的每一个点转换到裁剪空间中。因此我们需要在顶点着色器中计算出每一个点的裁切空间坐标并且将其传给Hull Stage。使用 GetVertexPositionInputs 就可以得到我们想要的了。
struct TessellationControlPoint {
float4 positionCS : SV_POSITION; // -- Edited --
...
};
TessellationControlPoint Vertex(Attributes input) {
TessellationControlPoint output;
...
VertexPositionInputs posnInputs = GetVertexPositionInputs(input.positionOS);
...
output.positionCS = posnInputs.positionCS; // -- Edited --
...
return output;
}然后在Patch Constant Function上方写一个测试函数,用于判断是否剔除该补丁。这里暂时传false。该函数传进来三个裁切空间的点。
// Returns true if it should be clipped due to frustum or winding culling
bool ShouldClipPatch(float4 p0PositionCS, float4 p1PositionCS, float4 p2PositionCS) {
return false;
}然后再编写 IsOutOfBounds 函数测试某个点是否超过边界。边界也是可以指定,在另一个函数中将这个方法利用起来,判断某个点是否在视锥体之外。
// Returns true if the point is outside the bounds set by lower and higher
bool IsOutOfBounds(float3 p, float3 lower, float3 higher) {
return p.x < lower.x || p.x > higher.x || p.y < lower.y || p.y > higher.y || p.z < lower.z || p.z > higher.z;
}
// Returns true if the given vertex is outside the camera fustum and should be culled
bool IsPointOutOfFrustum(float4 positionCS) {
float3 culling = positionCS.xyz;
float w = positionCS.w;
// UNITY_RAW_FAR_CLIP_VALUE is either 0 or 1, depending on graphics API
// Most use 0, however OpenGL uses 1
float3 lowerBounds = float3(-w, -w, -w * UNITY_RAW_FAR_CLIP_VALUE);
float3 higherBounds = float3(w, w, w);
return IsOutOfBounds(culling, lowerBounds, higherBounds);
}在裁切空间(Clip Space)中,W分量是其次坐标,可以决定点是否在视锥体中。如果xyz超出了 [-w, w] 的范围,这些点就会被剔除,因为他们在视锥体之外。不同的API在深度的处理上有不同的逻辑,我们用这个分量作为边界的时候需要注意。DirectX和Vulkan使用左手系,Clip深度是 [0, 1] ,所以UNITY_RAW_FAR_CLIP_VALUE是0。OpenGL是右手系,Clip深度范围 [-1, 1] ,UNITY_RAW_FAR_CLIP_VALUE是1。
准备好这些后,就可以判断一个Patch是否需要剔除了。回到刚开始的函数,在这个函数中判断一个Patch的所有点是否需要剔除。
// Returns true if it should be clipped due to frustum or winding culling
bool ShouldClipPatch(float4 p0PositionCS, float4 p1PositionCS, float4 p2PositionCS) {
bool allOutside = IsPointOutOfFrustum(p0PositionCS) &&
IsPointOutOfFrustum(p1PositionCS) &&
IsPointOutOfFrustum(p2PositionCS); // -- Edited --
return allOutside; // -- Edited --
}3.2 背面剔除
Patch除了经历视锥体剔除,还可以做一个背面剔除。用法向量来判断Patch是否需要剔除。

用两个向量做叉积就得到法向量。由于当前在Clip空间,需要做一个透视除法,得到NDC,这个范围应该是 [-1,1] 的。需要转换到NDC的原因是,在Clip空间中的位置是非线性的,这有可能导致顶点的位置的扭曲,转换到NDC这样的线性空间能更加准确的判断顶点的前后关系。
// Returns true if the points in this triangle are wound counter-clockwise
bool ShouldBackFaceCull(float4 p0PositionCS, float4 p1PositionCS, float4 p2PositionCS) {
float3 point0 = p0PositionCS.xyz / p0PositionCS.w;
float3 point1 = p1PositionCS.xyz / p1PositionCS.w;
float3 point2 = p2PositionCS.xyz / p2PositionCS.w;
float3 normal = cross(point1 - point0, point2 - point0);
return dot(normal, float3(0, 0, 1)) < 0;
}上面的代码还存在一个跨平台问题。观察方向在不同API的朝向是不同的,因此修改一下代码。
// In clip space, the view direction is float3(0, 0, 1), so we can just test the z coord
#if UNITY_REVERSED_Z
return cross(point1 - point0, point2 - point0).z < 0;
#else // In OpenGL, the test is reversed
return cross(point1 - point0, point2 - point0).z > 0;
#endif最后的最后,在 ShouldClipPatch 中添加刚写好的函数用于判断背面剔除。
// Returns true if it should be clipped due to frustum or winding culling
bool ShouldClipPatch(float4 p0PositionCS, float4 p1PositionCS, float4 p2PositionCS) {
bool allOutside = IsPointOutOfFrustum(p0PositionCS) &&
IsPointOutOfFrustum(p1PositionCS) &&
IsPointOutOfFrustum(p2PositionCS);
return allOutside || ShouldBackFaceCull(p0PositionCS, p1PositionCS, p2PositionCS); // -- Edited --
}然后在 PatchConstantFunction 中将需要剔除的Patch的顶点因子设置为0 。
...
if (ShouldClipPatch(patch[0].positionCS, patch[1].positionCS, patch[2].positionCS)) {
f.edge[0] = f.edge[1] = f.edge[2] = f.inside = 0; // Cull the patch
}
...3.3 增加容差
你可能想验证代码正确性,也可能会有一些意外剔除的情况。此时增加一个容差tolerance是一个灵活的办法。
首先是视锥体剔除容差。如果容差是正值,那么剔除边界会扩展,这样一些位于视锥体边缘附近的物体即使部分越界也不会被剔除。这种方法可以减少因为小的视角变动或物体动态而频繁变化的剔除状态。
// Returns true if the given vertex is outside the camera fustum and should be culled
bool IsPointOutOfFrustum(float4 positionCS, float tolerance) {
float3 culling = positionCS.xyz;
float w = positionCS.w;
// UNITY_RAW_FAR_CLIP_VALUE is either 0 or 1, depending on graphics API
// Most use 0, however OpenGL uses 1
float3 lowerBounds = float3(-w - tolerance, -w - tolerance, -w * UNITY_RAW_FAR_CLIP_VALUE - tolerance);
float3 higherBounds = float3(w + tolerance, w + tolerance, w + tolerance);
return IsOutOfBounds(culling, lowerBounds, higherBounds);
}接着调整背面剔除。在实际操作中,通过与容差而不是零进行比较,可以避免由于数值计算精度带来的问题。如果点积结果小于某个小的正值(容差),而不是严格小于零,那么图元被视为背面。这种方法提供了额外的缓冲区,确保只有明确的背面图元被剔除。
// Returns true if the points in this triangle are wound counter-clockwise
bool ShouldBackFaceCull(float4 p0PositionCS, float4 p1PositionCS, float4 p2PositionCS, float tolerance) {
float3 point0 = p0PositionCS.xyz / p0PositionCS.w;
float3 point1 = p1PositionCS.xyz / p1PositionCS.w;
float3 point2 = p2PositionCS.xyz / p2PositionCS.w;
// In clip space, the view direction is float3(0, 0, 1), so we can just test the z coord
#if UNITY_REVERSED_Z
return cross(point1 - point0, point2 - point0).z < -tolerance;
#else // In OpenGL, the test is reversed
return cross(point1 - point0, point2 - point0).z > tolerance;
#endif
}可以在材质面板中暴露一个Range。
// .shader
Properties{
_tolerance("_tolerance",Range(-0.002,0.001)) = 0
...
}
// .hlsl
float _tolerance;
...
// Returns true if it should be clipped due to frustum or winding culling
bool ShouldClipPatch(float4 p0PositionCS, float4 p1PositionCS, float4 p2PositionCS) {
bool allOutside = IsPointOutOfFrustum(p0PositionCS, _tolerance) &&
IsPointOutOfFrustum(p1PositionCS, _tolerance) &&
IsPointOutOfFrustum(p2PositionCS, _tolerance); // -- Edited --
return allOutside || ShouldBackFaceCull(p0PositionCS, p1PositionCS, p2PositionCS,_tolerance); // -- Edited --
}
3.4 动态细分因子
目前为止,我们的算法是无差别地细分所有的表面。但在一个复杂的Mesh中,可能会出现大小面的情况,即Mesh面积不均的情况。大面由于面积大,在视觉上更为明显,需要更多的细分来保证表面的平滑度和细节。小面由于面积小,可以考虑减少这个部分的细分程度,不会对视觉效果带来太大的影响。根据变长来动态改变因子是比较常见的方法。设置一个算法,让边长较长的面拥有更高的细分因子。
除了Mesh自身的大小面以外,摄像机与Patch的距离也可以作为动态改变因子的因素。距离摄像机较远的对象可以降低细分因子,因为在屏幕上占据的像素数较少。还可以根据用户的视角和视线方向,可以优先细分那些面向摄像机的面,而对背对摄像机或侧面的部分降低细分程度。
3.4.1 固定的细分缩放
获取两个顶点的距离。距离越大,细分的因子就越大。scale暴露在控制面板将其设置为 [0,1] ,scale是1时,细分因子直接由两点距离贡献。scale越接近0,细分因子越大。另外加上一个初值bias。最后让因此取1或以上的数,确保准确性。
// Calculate the tessellation factor for an edge
float EdgeTessellationFactor(float scale, float bias, float3 p0PositionWS, float3 p1PositionWS) {
float factor = distance(p0PositionWS, p1PositionWS) / scale;
return max(1, factor + bias);
}然后修改材质面板和Patch Constant Function。一般来说,采用边缘细分因子的平均值作为内部细分因子,视觉效果比较连贯。
// .shader
Properties{
...
_TessellationBias("_TessellationBias", Range(-1,5)) = 1
_TessellationFactor("_TessellationFactor", Range(0,1)) = 0
}
// .hlsl
f.edge[0] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[1].positionWS, patch[2].positionWS);
f.edge[1] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[2].positionWS, patch[0].positionWS);
f.edge[2] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[0].positionWS, patch[1].positionWS);
f.inside = (f.edge[0] + f.edge[1] + f.edge[2]) / 3.0;不同尺寸的片元其细分程度会动态变化,效果如下。

对了,如果发现你的内部因子图案非常奇怪,这可能是编译器导致的,尝试将内部因子代码修改为以下就可以解决。
f.inside = ( // If the compiler doesn't play nice...
EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[1].positionWS, patch[2].positionWS) +
EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[2].positionWS, patch[0].positionWS) +
EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[0].positionWS, patch[1].positionWS)
) / 3.0;3.4.2 屏幕空间细分缩放
接下来加入摄像机距离的判断。我们可以直接用屏幕空间的距离来调整细分程度,这样完美地同时处理了大小面+屏幕距离的问题!
由于我们已经有了Clip空间的数据。由于屏幕空间与NDC空间非常相似,只需要换到NDC就可以了,即做一个透视除法。
float EdgeTessellationFactor(float scale, float bias, float3 p0PositionWS, float4 p0PositionCS, float3 p1PositionWS, float4 p1PositionCS) {
float factor = distance(p0PositionCS.xyz / p0PositionCS.w, p1PositionCS.xyz / p1PositionCS.w) / scale;
return max(1, factor + bias);
}接下来在Patch Constant Function中传入Clip空间的坐标。
f.edge[0] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias,
patch[1].positionWS, patch[1].positionCS, patch[2].positionWS, patch[2].positionCS);
f.edge[1] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias,
patch[2].positionWS, patch[2].positionCS, patch[0].positionWS, patch[0].positionCS);
f.edge[2] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias,
patch[0].positionWS, patch[0].positionCS, patch[1].positionWS, patch[1].positionCS);
f.inside = (f.edge[0] + f.edge[1] + f.edge[2]) / 3.0;当前的效果相当的不错,随着摄像机的距离(屏幕空间的距离)的变化,细分程度也会动态变化。如果使用INTEGER意外的划分模式,会得到更连贯的效果。

还有一些地方可以改进。比如缩放系数的单位。方才我们将其控制在 [0,1] ,其实并不是很适合我们去调整。我们乘上一个屏幕分辨率,然后将缩放系数范围改为 [0,1080] ,更方便我们调整。然后修改一下材质面板属性。现在就是以像素为单位的比例了。
// .hlsl
float factor = distance(p0PositionCS.xyz / p0PositionCS.w, p1PositionCS.xyz / p1PositionCS.w) * _ScreenParams.y / scale;
// .shader
_TessellationFactor("_TessellationFactor",Range(0,1080)) = 320
3.4.3 相机距离细分缩放
我们怎么采用相机距离缩放呢?非常简单,计算 「两点间的距离」与「两顶点的中点与相机位置的距离」的比值。比值越大说明占据屏幕的空间就越大,需要更多的细分程度。
// .hlsl
float EdgeTessellationFactor(float scale, float bias, float3 p0PositionWS, float3 p1PositionWS) {
float length = distance(p0PositionWS, p1PositionWS);
float distanceToCamera = distance(GetCameraPositionWS(), (p0PositionWS + p1PositionWS) * 0.5);
float factor = length / (scale * distanceToCamera * distanceToCamera);
return max(1, factor + bias);
}
...
f.edge[0] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[1].positionWS, patch[2].positionWS);
f.edge[1] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[2].positionWS, patch[0].positionWS);
f.edge[2] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, patch[0].positionWS, patch[1].positionWS);
// .shader
_TessellationFactor("_TessellationFactor",Range(0, 1)) = 0.02注意,此时的缩放因子单位不再是像素,而是用最开始的 [0,1] 。因为这个方法,屏幕像素意义不是特别大,所以就不用了。并且用回了世界坐标。
屏幕空间细分缩放和相机距离细分缩放的结果比较相似,一般可以开放一个宏来切换上面几种动态因子的模式。这里就留给读者自行完成。
3.5 指定细分因子
3.5.1 顶点存储细分因子
上一节中,我们使用不同的策略猜测适当的细分因子。如果我们确切知道该Mesh应该怎么细分,那么可以在Mesh中存储这些细分因子的系数。由于系数只需要一个float,因此只需要用到一个颜色通道就可以了。下面是一个伪代码,感受一下就行。
float EdgeTessellationFactor(float scale, float bias, float multiplier) {
...
return max(1, (factor + bias) * multiplier);
}
...
// PCF()
[unroll] for (int i = 0; i < 3; i++) {
multipliers[i] = patch[i].color.g;
}
// Calculate tessellation factors
f.edge[0] = EdgeTessellationFactor(_TessellationFactor, _TessellationBias, (multipliers[1] + multipliers[2]) / 2);
3.5.2 SDF控制曲面细分因子
结合有符号距离场(Signed Distance Field, SDF)来控制曲面细分(Tessellation)因子,相当的酷炫。当然本节不涉及SDF的生成,假设能够直接通过现成的函数 CalculateSDFDistance 获取。
对于给定的Mesh,用 CalculateSDFDistance 计算出每个Patch中各个顶点到SDF表示的形状(例如球体)的距离。得到距离后再评估该Patch的细分需求,进行细分。
TessellationFactors PatchConstantFunction(
InputPatch<TessellationControlPoint, 3> patch) {
float multipliers[3];
// 循环处理每个顶点
[unroll] for (int i = 0; i < 3; i++) {
// 计算每个顶点到SDF表面的距离
float sdfDistance = CalculateSDFDistance(patch[i].positionWS);
// 根据SDF距离调整细分因子
if (sdfDistance < _TessellationDistanceThreshold) {
multipliers[i] = lerp(_MinTessellationFactor, _MaxTessellationFactor, (1 - sdfDistance / _TessellationDistanceThreshold));
} else {
multipliers[i] = _MinTessellationFactor;
}
}
// 计算最终的细分因子
TessellationFactors f;
f.Edge[0] = max(multipliers[0], multipliers[1]);
f.Edge[1] = max(multipliers[1], multipliers[2]);
f.Edge[2] = max(multipliers[2], multipliers[0]);
f.Inside = (multipliers[0] + multipliers[1] + multipliers[2]) / 3;
return f;
}具体实现我也不会,先庄懂一下。

四、顶点偏移 – 轮廓平滑
为一个Mesh添加细节最简单的方法是上各种高分辨率贴图。但是底大一级压死人,说的就是增加Mesh顶点的效果比增加贴图分辨率的效果要好。举个例子,法线贴图虽然可以改变每一个片元的法线方向,但是并不会改变几何外观。就算是128K的纹理也无法消除锯齿和pointy的边缘。

因此需要上曲面细分,然后偏移顶点。刚刚提到的所有曲面细分操作都是在Patch所在的平面上操作的。如果我们想要弯曲这些顶点,一个最简单的操作就是Phong细分。
4.1 Phong细分
首先附上原论文。https://perso.telecom-paristech.fr/boubek/papers/PhongTessellation/PhongTessellation.pdf
Phong着色应该很熟悉,是一种利用法向量线性差值得到平滑的着色的技术。Phong细分的灵感来自Phong着色,将Phong着色这一概念扩展到空间域。
Phong细分的核心思想是利用三角形每个角的顶点法线来影响细分过程中新顶点的位置,从而创造出曲面而非平面。
值得注意一下,这里很多教程会用triangle corner(三角形的角)来表示顶点,我觉得都差不多,本文还是用回顶点。
首先,在Domain函数内unity会给我们当前需要处理的新顶点的重心坐标。假设我们现在处理的是 (13,13,13) 。

Patch的每一个顶点都有法线。想象从每一个顶点发出一个切平面,垂直于各自的法向量。


然后将当前的顶点分别投影到这三个切平面上。

用数学语言描述。 P′=P−((P−V)⋅N)N
其中 :
- $P$ 是最初插值的平面位置。
- $V$ 是平面上的一个顶点位置。
- $N$ 是顶点 $V$ 处的法线。
- ⋅ 表示点积。
- P′ 是 $P$ 在平面上的投影。
得到三个 $P’$ 。


投影在三个切平面的三个点重新组成一个新的三角形,再用回当前顶点的重心坐标应用到新的三角形上,计算出新的点。

// Calculate Phong projection offset
float3 PhongProjectedPosition(float3 flatPositionWS, float3 cornerPositionWS, float3 normalWS) {
return flatPositionWS - dot(flatPositionWS - cornerPositionWS, normalWS) * normalWS;
}
// Apply Phong smoothing
float3 CalculatePhongPosition(float3 bary, float3 p0PositionWS, float3 p0NormalWS,
float3 p1PositionWS, float3 p1NormalWS, float3 p2PositionWS, float3 p2NormalWS) {
float3 smoothedPositionWS =
bary.x * PhongProjectedPosition(flatPositionWS, p0PositionWS, p0NormalWS) +
bary.y * PhongProjectedPosition(flatPositionWS, p1PositionWS, p1NormalWS) +
bary.z * PhongProjectedPosition(flatPositionWS, p2PositionWS, p2NormalWS);
return smoothedPositionWS;
}
// The domain function runs once per vertex in the final, tessellated mesh
// Use it to reposition vertices and prepare for the fragment stage
[domain("tri")] // Signal we're inputting triangles
Interpolators Domain(
TessellationFactors factors, // The output of the patch constant function
OutputPatch<TessellationControlPoint, 3> patch, // The Input triangle
float3 barycentricCoordinates : SV_DomainLocation) { // The barycentric coordinates of the vertex on the triangle
Interpolators output;
...
float3 positionWS = CalculatePhongPosition(barycentricCoordinates,
patch[0].positionWS, patch[0].normalWS,
patch[1].positionWS, patch[1].normalWS,
patch[2].positionWS, patch[2].normalWS);
float3 normalWS = BARYCENTRIC_INTERPOLATE(normalWS);
float3 tangentWS = BARYCENTRIC_INTERPOLATE(tangentWS.xyz);
...
output.positionCS = TransformWorldToHClip(positionWS);
output.normalWS = normalWS;
output.positionWS = positionWS;
output.tangentWS = float4(tangentWS, patch[0].tangentWS.w);
...
}注意这里需要添加法线向量,然后写进Vertex和Domain。再写一个计算算 $P’$ 重心坐标的函数。
struct Attributes {
...
float4 tangentOS : TANGENT;
};
struct TessellationControlPoint {
...
float4 tangentWS : TANGENT;
};
struct Interpolators {
...
float4 tangentWS : TANGENT;
};
TessellationControlPoint Vertex(Attributes input) {
TessellationControlPoint output;
...
// .....最后一个是符号系数
output.tangentWS = float4(normalInputs.tangentWS, input.tangentOS.w); // tangent.w containts bitangent multiplier
}
// Barycentric interpolation as a function
float3 BarycentricInterpolate(float3 bary, float3 a, float3 b, float3 c) {
return bary.x * a + bary.y * b + bary.z * c;
}
在Phong细分原论文中,还加入了一个 α 因子,用于控制弯曲的程度。原文作者推荐将这个数值全局地设置为四分之三,这样的视觉效果最好。将含有 α 因子的算法展开后可以得到二次贝塞尔曲线,虽然不能提供拐点但是实际开发中已经足够使用。

首先看看原论文的公式。

本质上就是控制插值的程度,定量分析一下就知道,当 α=0 的时候,所有顶点都在原来的平面上,也就相当于没有任何位移。当 α=1 的时候,新的顶点完全依赖于Phong细分弯曲顶点。当然,你也可以尝试小于零或者大于一的数值,效果也是比较有趣的。~~看不懂原文的数学公式没关系,我反手直接上一个lerp,主打一个胡乱插值。~~
// Apply Phong smoothing
float3 CalculatePhongPosition(float3 bary, float smoothing, float3 p0PositionWS, float3 p0NormalWS,
float3 p1PositionWS, float3 p1NormalWS, float3 p2PositionWS, float3 p2NormalWS) {
float3 flatPositionWS = BarycentricInterpolate(bary, p0PositionWS, p1PositionWS, p2PositionWS);
float3 smoothedPositionWS =
bary.x * PhongProjectedPosition(flatPositionWS, p0PositionWS, p0NormalWS) +
bary.y * PhongProjectedPosition(flatPositionWS, p1PositionWS, p1NormalWS) +
bary.z * PhongProjectedPosition(flatPositionWS, p2PositionWS, p2NormalWS);
return lerp(flatPositionWS, smoothedPositionWS, smoothing);
}
// Apply Phong smoothing
float3 CalculatePhongPosition(float3 bary, float smoothing, float3 p0PositionWS, float3 p0NormalWS,
float3 p1PositionWS, float3 p1NormalWS, float3 p2PositionWS, float3 p2NormalWS) {
float3 flatPositionWS = BarycentricInterpolate(bary, p0PositionWS, p1PositionWS, p2PositionWS);
float3 smoothedPositionWS =
bary.x * PhongProjectedPosition(flatPositionWS, p0PositionWS, p0NormalWS) +
bary.y * PhongProjectedPosition(flatPositionWS, p1PositionWS, p1NormalWS) +
bary.z * PhongProjectedPosition(flatPositionWS, p2PositionWS, p2NormalWS);
return lerp(flatPositionWS, smoothedPositionWS, smoothing);
}别忘了暴露在材质面板中。
// .shader
_TessellationSmoothing("_TessellationSmoothing", Range(0,1)) = 0.5
// .hlsl
float _TessellationSmoothing;
Interpolators Domain( .... ) {
...
float smoothing = _TessellationSmoothing;
float3 positionWS = CalculatePhongPosition(barycentricCoordinates, smoothing,
patch[0].positionWS, patch[0].normalWS,
patch[1].positionWS, patch[1].normalWS,
patch[2].positionWS, patch[2].normalWS);
...
}
需要特别注意的是,有些模型需要一些修饰。如果模型的边缘非常锐利,那么就说明这个顶点的法线和所在面的法线几乎平行。在Phong Tessellation中,这会导致顶点在切平面上的投影非常接近于原始的顶点位置,从而使得细分的影响减少。
为了解决这个问题,可以在建模软件中进行所谓的“添加环边”(adding loop edges)或“环切割”(loop cut),以添加更多的几何细节。在原模型的边缘附近插入额外的边缘环,从而增加细分密度。具体操作这里就不展开了。
总的来说,Phong细分的效果和性能都相对不错。但是如果希望得到更高品质的平滑效果,可以考虑 PN triangles。该技术基于贝塞尔曲线弯曲三角形。
4.2 PN triangles 细分
首先附上原论文。http://alex.vlachos.com/graphics/CurvedPNTriangles.pdf
PN Triangles不需要邻近三角形的信息,并且成本较低。PN Triangles算法只需要Patch里的三个顶点的位置和法线信息。剩下的数据都可以通过计算得到。注意,所有数据都在重心坐标。
在PN算法中,需要先计算出10个控制点用于曲面细分,如下图所示。三个三角形的顶点,一个重心,还有三对边上的控制点组成所有控制点。计算得到的贝塞尔曲线控制点,会传给Domain。由于每个三角形Patch的控制点都是一致的,因此计算控制点的步骤放在Patch Constant Function非常合适。

论文中的计算方式如下:
$$
\begin{aligned}
b_{300} & =P_1 \
b_{030} & =P_2 \
b_{003} & =P_3 \
w_{i j} & =\left(P_j-P_i\right) \cdot N_i \in \mathbf{R} \quad \text { here ‘ } \cdot \text { ‘ is the scalar product, } \
b_{210} & =\left(2 P_1+P_2-w_{12} N_1\right) / 3 \
b_{120} & =\left(2 P_2+P_1-w_{21} N_2\right) / 3 \
b_{021} & =\left(2 P_2+P_3-w_{23} N_2\right) / 3 \
b_{012} & =\left(2 P_3+P_2-w_{32} N_3\right) / 3 \
b_{102} & =\left(2 P_3+P_1-w_{31} N_3\right) / 3, \
b_{201} & =\left(2 P_1+P_3-w_{13} N_1\right) / 3, \
E & =\left(b_{210}+b_{120}+b_{021}+b_{012}+b_{102}+b_{201}\right) / 6 \
V & =\left(P_1+P_2+P_3\right) / 3, \
b_{111} & =E+(E-V) / 2 .
\end{aligned}
$$
公式中的 $w_{i j}$ 每条边都会计算两次,因此一共会计算6次。比如 $w_{1 2}$ 的意义就是,$P_1$ 到 $P_2$ 的向量在 $P_1$ 法线方向上的投影长度。再乘上对应的法线方向就表示 $w$ 为长度的投影向量。
还是计算靠近 $P_1$ 的因子为例,当前位置点的权重应该较大,乘上一个 $2$ 使得计算出来的控制点更加靠近当前的顶点。减去投影向量的原因是为了修正因 $P_2$ 位置不在 $P_1$ 法线定义的平面上而导致的误差。让三角形平面更加吻合,减少扭曲效果。最后再除3,为了标准化。
接着计算平均贝塞尔控制点 $E$ ,表示六个控制点的平均位置。这个平均位置代表了边界控制点的集中趋势。然后算一下三角形顶点的平均位置。然后求出这两个平均位置的中点位置,加到贝塞尔平均控制点。这就是最终要求的第十个参数了。
总结一下,前三个是三角形的顶点位置(因此不用写在结构体里面),有六个是通过权重计算,最后一个是集合前面计算的平均起来。代码书写非常简单。
struct TessellationFactors {
float edge[3] : SV_TessFactor;
float inside : SV_InsideTessFactor;
float3 bezierPoints[7] : BEZIERPOS;
};
//Bezier control point calculations
float3 CalculateBezierControlPoint(float3 p0PositionWS, float3 aNormalWS, float3 p1PositionWS, float3 bNormalWS) {
float w = dot(p1PositionWS - p0PositionWS, aNormalWS);
return (p0PositionWS * 2 + p1PositionWS - w * aNormalWS) / 3.0;
}
void CalculateBezierControlPoints(inout float3 bezierPoints[7],
float3 p0PositionWS, float3 p0NormalWS, float3 p1PositionWS, float3 p1NormalWS, float3 p2PositionWS, float3 p2NormalWS) {
bezierPoints[0] = CalculateBezierControlPoint(p0PositionWS, p0NormalWS, p1PositionWS, p1NormalWS);
bezierPoints[1] = CalculateBezierControlPoint(p1PositionWS, p1NormalWS, p0PositionWS, p0NormalWS);
bezierPoints[2] = CalculateBezierControlPoint(p1PositionWS, p1NormalWS, p2PositionWS, p2NormalWS);
bezierPoints[3] = CalculateBezierControlPoint(p2PositionWS, p2NormalWS, p1PositionWS, p1NormalWS);
bezierPoints[4] = CalculateBezierControlPoint(p2PositionWS, p2NormalWS, p0PositionWS, p0NormalWS);
bezierPoints[5] = CalculateBezierControlPoint(p0PositionWS, p0NormalWS, p2PositionWS, p2NormalWS);
float3 avgBezier = 0;
[unroll] for (int i = 0; i < 6; i++) {
avgBezier += bezierPoints[i];
}
avgBezier /= 6.0;
float3 avgControl = (p0PositionWS + p1PositionWS + p2PositionWS) / 3.0;
bezierPoints[6] = avgBezier + (avgBezier - avgControl) / 2.0;
}
// The patch constant function runs once per triangle, or "patch"
// It runs in parallel to the hull function
TessellationFactors PatchConstantFunction(
InputPatch<TessellationControlPoint, 3> patch) {
...
TessellationFactors f = (TessellationFactors)0;
// Check if this patch should be culled (it is out of view)
if (ShouldClipPatch(...)) {
...
} else {
...
CalculateBezierControlPoints(f.bezierPoints, patch[0].positionWS, patch[0].normalWS,
patch[1].positionWS, patch[1].normalWS, patch[2].positionWS, patch[2].normalWS);
}
return f;
}接着在domain函数中,使用Hull Function输出的十个因子。根据论文给出的公式,计算出最终的立方贝塞尔曲面坐标。然后再插值一下,暴露到材质面板上。
$$
\begin{aligned}
& b: \quad R^2 \mapsto R^3, \quad \text { for } w=1-u-v, \quad u, v, w \geq 0 \
& b(u, v)= \sum_{i+j+k=3} b_{i j k} \frac{3!}{i!j!k!} u^i v^j w^k \
&= b_{300} w^3+b_{030} u^3+b_{003} v^3 \
&+b_{210} 3 w^2 u+b_{120} 3 w u^2+b_{201} 3 w^2 v \
&+b_{021} 3 u^2 v+b_{102} 3 w v^2+b_{012} 3 u v^2 \
&+b_{111} 6 w u v .
\end{aligned}
$$
// Barycentric interpolation as a function
float3 BarycentricInterpolate(float3 bary, float3 a, float3 b, float3 c) {
return bary.x * a + bary.y * b + bary.z * c;
}
float3 CalculateBezierPosition(float3 bary, float smoothing, float3 bezierPoints[7],
float3 p0PositionWS, float3 p1PositionWS, float3 p2PositionWS) {
float3 flatPositionWS = BarycentricInterpolate(bary, p0PositionWS, p1PositionWS, p2PositionWS);
float3 smoothedPositionWS =
p0PositionWS * (bary.x * bary.x * bary.x) +
p1PositionWS * (bary.y * bary.y * bary.y) +
p2PositionWS * (bary.z * bary.z * bary.z) +
bezierPoints[0] * (3 * bary.x * bary.x * bary.y) +
bezierPoints[1] * (3 * bary.y * bary.y * bary.x) +
bezierPoints[2] * (3 * bary.y * bary.y * bary.z) +
bezierPoints[3] * (3 * bary.z * bary.z * bary.y) +
bezierPoints[4] * (3 * bary.z * bary.z * bary.x) +
bezierPoints[5] * (3 * bary.x * bary.x * bary.z) +
bezierPoints[6] * (6 * bary.x * bary.y * bary.z);
return lerp(flatPositionWS, smoothedPositionWS, smoothing);
}
// The domain function runs once per vertex in the final, tessellated mesh
// Use it to reposition vertices and prepare for the fragment stage
[domain("tri")] // Signal we're inputting triangles
Interpolators Domain(
TessellationFactors factors, // The output of the patch constant function
OutputPatch<TessellationControlPoint, 3> patch, // The Input triangle
float3 barycentricCoordinates : SV_DomainLocation) { // The barycentric coordinates of the vertex on the triangle
Interpolators output;
...
// Calculate tessellation smoothing multipler
float smoothing = _TessellationSmoothing;
#ifdef _TESSELLATION_SMOOTHING_VCOLORS
smoothing *= BARYCENTRIC_INTERPOLATE(color.r); // Multiply by the vertex's red channel
#endif
float3 positionWS = CalculateBezierPosition(barycentricCoordinates,
smoothing, factors.bezierPoints,
patch[0].positionWS, patch[1].positionWS, patch[2].positionWS);
float3 normalWS = BARYCENTRIC_INTERPOLATE(normalWS);
float3 tangentWS = BARYCENTRIC_INTERPOLATE(tangentWS.xyz);
...
}
对比效果,关闭与开启PN triangles。
4.3 改进版 PN triangles – 输出细分的法线
传统的PN triangles只改变了顶点的位置信息,我们可以再结合顶点的法线信息,输出动态变化的法线信息,提供更好的光线反射效果。
在原本的的算法中,法线的变化是非常离散的。如下图(上)所示,利用原本三角形的两个顶点提供的法线也许不能很好的表现原本曲面的法线变化。我们想要达到下图(下)的效果,因此需要利用二次插值得到单个Patch中可能的曲面变化。
由于曲面是三次贝塞尔面,所以法线应该是二次贝塞尔曲面插值。因此需要额外的三个法线控制点。TheTus的文章已经讲得比较清晰了,详细的数学原理请移步Ref10.链接。

下面简单介绍一下如何获取细分的法线方向。
首先获取点AB的两个法线信息。然后求出他们的平均法向。

构造一个垂直于线段AB过中点的平面。

取刚刚平均法向对于该平面的反射向量。

每条边都算一下,算三个。

struct TessellationFactors {
float edge[3] : SV_TessFactor;
float inside : SV_InsideTessFactor;
float3 bezierPoints[10] : BEZIERPOS;
};
float3 CalculateBezierControlNormal(float3 p0PositionWS, float3 aNormalWS, float3 p1PositionWS, float3 bNormalWS) {
float3 d = p1PositionWS - p0PositionWS;
float v = 2 * dot(d, aNormalWS + bNormalWS) / dot(d, d);
return normalize(aNormalWS + bNormalWS - v * d);
}
void CalculateBezierNormalPoints(inout float3 bezierPoints[10],
float3 p0PositionWS, float3 p0NormalWS, float3 p1PositionWS, float3 p1NormalWS, float3 p2PositionWS, float3 p2NormalWS) {
bezierPoints[7] = CalculateBezierControlNormal(p0PositionWS, p0NormalWS, p1PositionWS, p1NormalWS);
bezierPoints[8] = CalculateBezierControlNormal(p1PositionWS, p1NormalWS, p2PositionWS, p2NormalWS);
bezierPoints[9] = CalculateBezierControlNormal(p2PositionWS, p2NormalWS, p0PositionWS, p0NormalWS);
}
// The patch constant function runs once per triangle, or "patch"
// It runs in parallel to the hull function
TessellationFactors PatchConstantFunction(
InputPatch<TessellationControlPoint, 3> patch) {
...
TessellationFactors f = (TessellationFactors)0;
// Check if this patch should be culled (it is out of view)
if (ShouldClipPatch(...)) {
..
} else {
...
CalculateBezierControlPoints(f.bezierPoints,
patch[0].positionWS, patch[0].normalWS, patch[1].positionWS,
patch[1].normalWS, patch[2].positionWS, patch[2].normalWS);
CalculateBezierNormalPoints(f.bezierPoints,
patch[0].positionWS, patch[0].normalWS, patch[1].positionWS,
patch[1].normalWS, patch[2].positionWS, patch[2].normalWS);
}
return f;
}并且需要注意,所有插值得到的法线向量都需要标准化。
float3 CalculateBezierNormal(float3 bary, float3 bezierPoints[10],
float3 p0NormalWS, float3 p1NormalWS, float3 p2NormalWS) {
return p0NormalWS * (bary.x * bary.x) +
p1NormalWS * (bary.y * bary.y) +
p2NormalWS * (bary.z * bary.z) +
bezierPoints[7] * (2 * bary.x * bary.y) +
bezierPoints[8] * (2 * bary.y * bary.z) +
bezierPoints[9] * (2 * bary.z * bary.x);
}
float3 CalculateBezierNormalWithSmoothFactor(float3 bary, float smoothing, float3 bezierPoints[10],
float3 p0NormalWS, float3 p1NormalWS, float3 p2NormalWS) {
float3 flatNormalWS = BarycentricInterpolate(bary, p0NormalWS, p1NormalWS, p2NormalWS);
float3 smoothedNormalWS = CalculateBezierNormal(bary, bezierPoints, p0NormalWS, p1NormalWS, p2NormalWS);
return normalize(lerp(flatNormalWS, smoothedNormalWS, smoothing));
}
// The domain function runs once per vertex in the final, tessellated mesh
// Use it to reposition vertices and prepare for the fragment stage
[domain("tri")] // Signal we're inputting triangles
Interpolators Domain(
TessellationFactors factors, // The output of the patch constant function
OutputPatch<TessellationControlPoint, 3> patch, // The Input triangle
float3 barycentricCoordinates : SV_DomainLocation) { // The barycentric coordinates of the vertex on the triangle
Interpolators output;
...
// Calculate tessellation smoothing multipler
float smoothing = _TessellationSmoothing;
float3 positionWS = CalculateBezierPosition(barycentricCoordinates, smoothing, factors.bezierPoints, patch[0].positionWS, patch[1].positionWS, patch[2].positionWS);
float3 normalWS = CalculateBezierNormalWithSmoothFactor(
barycentricCoordinates, smoothing, factors.bezierPoints,
patch[0].normalWS, patch[1].normalWS, patch[2].normalWS);
float3 tangentWS = BARYCENTRIC_INTERPOLATE(tangentWS.xyz);
...
}还有一个问题需要注意,当我们使用了插值得到的法线,与之一一对应的切线向量就不再与插值得到的法线向量正交。为了保持正交性,需要重新计算一个切线向量。
void CalculateBezierNormalAndTangent(
float3 bary, float smoothing, float3 bezierPoints[10],
float3 p0NormalWS, float3 p0TangentWS,
float3 p1NormalWS, float3 p1TangentWS,
float3 p2NormalWS, float3 p2TangentWS,
out float3 normalWS, out float3 tangentWS) {
float3 flatNormalWS = BarycentricInterpolate(bary, p0NormalWS, p1NormalWS, p2NormalWS);
float3 smoothedNormalWS = CalculateBezierNormal(bary, bezierPoints, p0NormalWS, p1NormalWS, p2NormalWS);
normalWS = normalize(lerp(flatNormalWS, smoothedNormalWS, smoothing));
float3 flatTangentWS = BarycentricInterpolate(bary, p0TangentWS, p1TangentWS, p2TangentWS);
float3 flatBitangentWS = cross(flatNormalWS, flatTangentWS);
tangentWS = normalize(cross(flatBitangentWS, normalWS));
}
[domain("tri")] // Signal we're inputting triangles
Interpolators Domain(
TessellationFactors factors, // The output of the patch constant function
OutputPatch<TessellationControlPoint, 3> patch, // The Input triangle
float3 barycentricCoordinates : SV_DomainLocation) { // The barycentric coordinates of the vertex on the triangle
...
float3 normalWS, tangentWS;
CalculateBezierNormalAndTangent(
barycentricCoordinates, smoothing, factors.bezierPoints,
patch[0].normalWS, patch[0].tangentWS.xyz,
patch[1].normalWS, patch[1].tangentWS.xyz,
patch[2].normalWS, patch[2].tangentWS.xyz,
normalWS, tangentWS);
...
}
References
- https://www.youtube.com/watch?v=63ufydgBcIk
- https://nedmakesgames.medium.com/mastering-tessellation-shaders-and-their-many-uses-in-unity-9caeb760150e
- https://zhuanlan.zhihu.com/p/148247621
- https://zhuanlan.zhihu.com/p/124235713
- https://zhuanlan.zhihu.com/p/141099616
- https://zhuanlan.zhihu.com/p/42550699
- https://en.wikipedia.org/wiki/Barycentric_coordinate_system
- https://zhuanlan.zhihu.com/p/359999755
- https://zhuanlan.zhihu.com/p/629364817
- https://zhuanlan.zhihu.com/p/629202115
- https://perso.telecom-paristech.fr/boubek/papers/PhongTessellation/PhongTessellation.pdf
- http://alex.vlachos.com/graphics/CurvedPNTriangles.pdf